Praktisks uzdevums: Filmu seansi Forum Cinemas kinoteātrī
Ievads
Šajā praktiskajā darbā jūs izveidosiet programmu automātiskai datu vākšanai par nākotnes seansiem kinoteātrī Forum Cinemas. Datu vākšanai jūs izmantosiet Python ar bibliotēku Selenium, bet saikņu saīsināšanai strādāsiet ar trešās puses API cleanuri.com. Papildus tam jūs izmantosiet versiju kontroles sistēmu Git caur termināli.
Sasniedzamie rezultāti
- Izmantot Git caur terminālu.
- Izmantot Selenium bibliotēku, lai iegūtu datus par seansiem kinoteātrī Forum Cinemas.
- Rakstīt un strukturēt Python kodu vairākos failos.
- Python izmantošana teksta failu izveidei.
- Izmantot requests bibliotēku un API cleanuri.com, lai saīsinātu saites.
1. Nepieciešamās programmas un rīki
Lai veiktu šo darbu, datorā ir jābūt instalētām šādām programmām:
- Python
- Git
- Visual Studio Code
- Python paplašinājums
Lai pārbaudītu, vai viss ir instalēts datorā, varat izmantot skriptu check.bat.
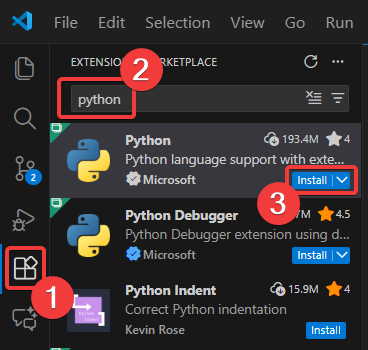
Lai instalētu Python paplašinājumu, atverot Visual Studio Code:
2. Darba uzsākšana ar Git un GitHub
GitHub repozitorija izveide
Veicot šo darbu, jums būs nepieciešams strādāt ar Git un GitHub.
Atveriet GitHub, ieietiet savā kontā un izveidojiet jaunu publisku repozitoriju (piemēram cinema-data), punktā Add .gitignore izvēlieties Python.

Git konfigurēšana
Šajā praktiskajā uzdevumā jums būs jāstrādā ar Git caur termināli. Atveriet Visual Studio Code un nospiediet Terminal > New Terminal.

Tagad pirms sākt izmantot Git, tas ir jākonfigurē. Mums ir jānorāda lietotājvārds un e-pasts, ko lietojam GitHub. Tas jādara, izmantojot komandas:
git config --global user.name "Your Name"
git config --global user.email email@example.com
Ievietojiet savu lietotājvārdu un e-pasta adresi šajās komandās.
Repozitorija klonēšana
Tagad mums ir jāpāriet uz vajadzīgo direktoriju (mapi) un jāklonē tur repozitorijs. Mēs to darīsim arī caur termināli. Šim nolūkam mēs izmantosim divas komandas: ls un cd.
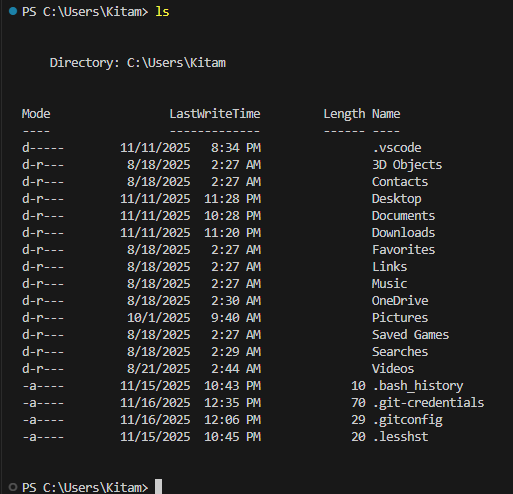
Komanda
lsparāda pašreizējā kataloga failu un mapju sarakstu.
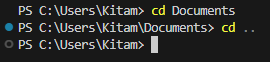
Komanda
cdļauj pāriet no vienas mapes uz citu, norādot tās ceļu. Lietojot.., komanda pāriet uz vecākmapi.
Jums ir jāpāriet uz mapi, kurā vēlaties novietot repozitoriju.
Kad pāriet, izmantojot komandu git clone, klonējiet repozitoriju, norādot saiti uz to. Piemēram:
git clone https://github.com/kitaminka/cinema-data
Pēc tam ar komandu code varat atvērt savu repozitoriju Visual Studio Code programmā, norādot direktorijas nosaukumu:
code cinema-data
Jums atvērsies vēl viens logs, iepriekšējo varat aizvērt.
3. Pievienojam bibliotēkas projektā
Ar nākamo komandu instalēsim requests un selenium bibliotēkas:
pip install requests selenium
Tagad ar nākamo komandu mēs varam saglabāt visu bibliotēku un to versiju sarakstu failā requirements.txt:
pip freeze > requirements.txt
requirements.txt faila piemērs:
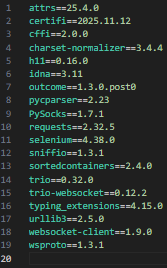
Projektos, kuros izmanto Python, ir pieņemts saglabāt visu izmantoto bibliotēku versijas failā
requirements.txt, lai citiem izstrādātājiem būtu vieglāk strādāt ar šo kodu.
4. Datu iegūšana ar Selenium palīdzību
Šajā uzdevumā mēs strukturēsim kodu dažādiem uzdevumiem dažādos failos. Failos būs dažādas funkcijas, kuras mēs pēc tam apvienosim vienā programmā.
Izveidojiet failu browser.py, kurā būs kods, kas saistīts ar datu ieguvi caur bibliotēku Selenium.
Ievietojiet tajā šādu kodu:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def get_films(): # Izveidojam funkciju get_films
driver = webdriver.Chrome()
driver.get("https://www.forumcinemas.lv/")
films = [] # Tukšs saraksts, kurā vēlāk pievienosim filmas.
# Saņemam saraksta veidā visus elementus, kuros ir informācija par filmu seansiem.
film_elements = driver.find_elements(By.CLASS_NAME, "show-list-item")
# Ciklā ejam pa elementu sarakstu ar informāciju par seansiem
for film in film_elements:
# SVARĪGI: šeit mēs meklējam elementu nevis visā lapā, bet jau elementā ar informāciju par filmu.
# Tāpēc mēs rakstām nevis driver.find_element(), bet gan film.find_element()
film_time = film.find_element(By.CLASS_NAME, "showTime")
# Pievienojiet šeit kodu, lai atrastu elementus lapā filmas, kas satur nosaukumu un saiti uz lapu filmas
film_name = ""
film_url = ""
# Papildiniet šo kodu tā, lai sarakstam tiktu pievienots arī filmas nosaukums un lapa.
films.append({ # Pievienojam informāciju par filmu sarakstā
"time": film_time.text, # Rakstam .text, jo vēlamies iegūt elementa saturu teksta veidā
# ...
})
driver.quit() # Aizveram pārlūka logu
Viss, kas rakstīts pēc simboliem
#, ir komentāri. Tie netiek izmantoti programmas darbībā un ir tikai paskaidrojumi labākai izpratnei.
Šajā programmā mēs meklējam elementus pēc klases nosaukuma. HTML kodā vienam elementam var būt vairākas klases, kā arī vienai klasei var būt vairāki elementi.
Piemēram, elementam, kas satur sesijas laiku, ir klase showTime, pēc kuras mēs to atrodam programmā (kā arī klase no-margin, kas ir arī citiem elementiem, tāpēc mēs nevaram to izmantot, lai atrastu konkrēti šo elementu):

Tagad jums pašiem ir jāpapildina programma tā, lai mēs atrastu arī elementus, kas satur filmas nosaukumu un saiti uz to. Lai to izdarītu, varat izmantot Selenium dokumentāciju un Google.
Lai redzētu, kādi elementi satur kādas vērtības, izmantojot Google Chrome var nospiest
Ctrl + Shift + Cun noklikšķināt uz interesējošo vērtību.
Padoms: zemāk redzams, ka saite uz filmu atrodas a tagā. Šim tagam nav klašu, bet to var atrast pēc tagu nosaukuma.

Kad pievienojāt kodu elementu meklēšanai, ir nepieciešams izvilkt no tiem informāciju un pievienot to sarakstam.
Filmas nosaukums atrodas viena no elementiem saturā, tāpēc tam var izmantot .text. Tomēr saite uz filmu jau atrodas href atribūtā, uzziniet paši no dokumentācijas vai Google, kā iegūt atribūta vērtību.
Filmas tiek pievienotas sarakstam vārdnīcas formātā. Vārdnīcā jābūt šādām atslēgām: name, url, time.

Tagad atliek papildināt funkciju tā, lai pēc pārlūka loga aizvēršanas tā atgrieztu filmu sarakstu. To var izdarīt, pievienojot rindu return films.
Lai pārbaudītu mūsu funkcijas darbību, mums tā ir jāizsauc. Pievienojiet faila beigās šādu kodu:
# Nākamā rinda ir nepieciešama, lai šis kods tiktu izpildīts tikai tad, kad mēs tieši palaistam šo failu
# Kad mēs importēsim funkciju get_films no citiem failiem, šis kods netiks izpildīts
if __name__ == "__main__":
print("Pārbaudām funkciju get_films")
print(get_films())
Mēģiniet palaist programmu, atkal atverot termināli un ievadot komandu python browser.py.
Terminālī jāparādās aptuveni šādam izvadam:
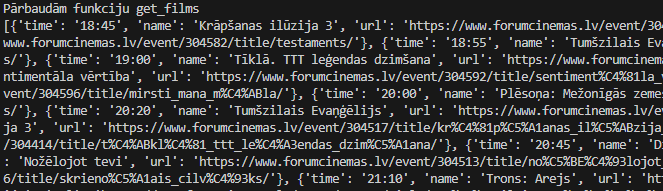
Ja viss darbojas, pievienojiet funkcijas sākumā šādu kodu:
options = Options()
options.add_argument("--headless=new")
Un arī izmainiet rindu, kur atveram pārlūku:
driver = webdriver.Chrome(options)
Tagad, ja jūs atkal palaidīsiet programmu, pārlūka logs būs neredzams.
5. Darbs ar komitiem un zariem
Komita izveide un to nosūtīšana uz GitHub
Komits ir konkrētā brīdī fiksēta projekta versija ar saglabātām izmaiņām un pievienotu īsu komentāru.
Tagad mums ir jānosūta kods uz GitHub. Lai to izdarītu, vispirms ir jāizveido komits. Vispirms ir jāpārbauda, kurus failus mēs mainījām. Lai to izdarītu, terminālī palaidiet komandu git status.
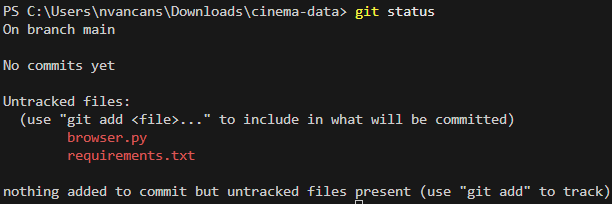
Mums ir jānorāda, kurus modificētos failus mēs vēlamies iekļaut komitā. To var izdarīt ar komandu git add, norādot failu nosaukumus.
Pēc tam, pārbaudot statusu, zaļā krāsā tiks atzīmēti faili, kas tiks iekļauti komitā.
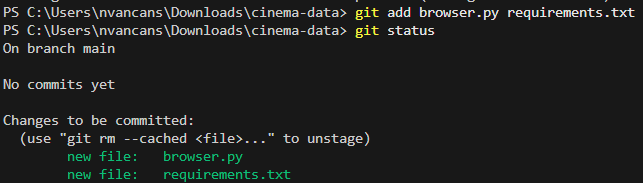
Tagad mēs varam veidot komitu ar komandu git commit. Lai norādītu ziņojumu komitam, ir jālieto arguments -m un pēc tā ziņojums.

Tagad varam nosūtīt šo komitu uz GitHub ar komandu git push.
Īsumā, lai izveidotu un nosūtītu komitu:
git add->git commit->git push
Izveidojam jaunu zaru
Git, ko mēs jau izmantojām, lai izveidotu komitu, piedāvā daudz dažādu funkciju versiju kontrolei. Viens no tiem ir zari. Mums var būt vairāki dažādi mūsu programmas varianti, kas tiek saukti par zariem.
Jums ir jāizveido zars save-to-file.
Komanda
git branchļauj apskatīt esošo zaru sarakstu, kā arī izveidot jaunu, norādot nosaukumu.
Komanda
git checkoutļauj pārslēgties starp zariem.
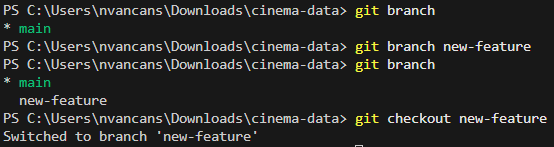
SVARĪGI: pirmoreiz, kad sūtīsiet komits jaunajā zarā, ir jānorāda papildu parametri, lai šis zars tiktu izveidots arī GitHub. Pēc pirmā komita ir jāieraksta komanda (neaizmirstiet nomainīt new-feature uz jūsu zara nosaukumu):
git push --set-upstream origin new-feature
Izveidojiet tukšu failu save.py, izveidojiet komitu un nosūtiet to.
6. Strādājam ar teksta failiem, izmantojot Python.
Python ļauj mums atvērt, lasīt un rediģēt failus. Pievienojiet failā save.py šādu kodu:
def save_films(films): # Izveidojam jaunu funkciju, kas pieņem filmu sarakstu
# Atveram failu ierakstīšanas režīmā
file = open("films.txt", "w", encoding="utf-8") # UTF-8 kodējums šeit ir nepieciešams, lai programma varētu pareizi strādāt ar latviešu simboliem.
for film in films: # Paņemam pa vienam filmu no saraksta ciklā
file.write("Film name: ") # Rakstām tekstu failā
file.write(film["name"]) # Ierakstām failā filmas nosaukumu
file.write("\n") # Pievienojam pāreju uz jaunu rindu failā
# ...
file.close() # Aizveram failu beigās
if __name__ == "__main__":
print("Pārbaudām funkciju save_films")
# Izmantojam testa datus, lai pārbaudītu funkciju
films = [
{
"name": "Film 1",
"time": "10:00",
"url": "https://example.com/film1"
},
{
"name": "Film 2",
"time": "12:00",
"url": "https://example.com/film2"
}
]
save_films(films)
Pamēģiniet palaist šo kodu. Tas izveidos failu films.txt un tajā ierakstīs filmu nosaukumus no testa datiem.
Papildiniet programmu tā, lai tā ierakstītu arī laiku un saiti uz filmu.
Kad esat to izdarījuši, papildiniet failu .gitignore, pievienojot beigās rindu films.txt. Tagad Git pilnībā ignorēs šo failu.
.gitignoreir saraksts ar failem vai mapēm, kurus Git ignorē.
Beigās izveidojiet un nosūtiet komitu.
7. Apvienojam funkcijas
Tagad izmantosim abas izveidotās funkcijas kopā. Pārslēdzieties uz main zaru.
Pārnesiet izmaiņas no iepriekš izveidotās zara uz main zaru.
git mergekomanda ļauj pārnest izmaiņas no citas zara uz aktīvo, norādot zara nosaukumu, no kura jāpārnes izmaiņas.
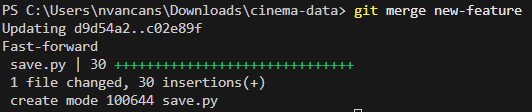
Izmantojiet git push, lai nosūtītu pārnestās izmaiņas.
Tagad izveidojiet failu main.py. Tas būs galvenais fails, kurā mēs importēsim visas izveidotās funkcijas un izmantosim tās.
Ierakstiet tajā šādu kodu:
# Importējam iepriekš izveidotas funkcijas
from browser import get_films
from save import save_films
if __name__ == "__main__":
films = get_films()
save_films(films)
Ja viss ir izdarīts pareizi, tad, palaižot programmu, tiks izveidots teksta fails ar informāciju par seansiem.
Atkal izveidojiet komitu un nosūtiet to uz GitHub.
8. Izveidojam funkciju saišu saīsināšanai
Izveidojiet url-shortener zaru un pārslēdzieties uz to.
Izveidojam failu url.py ar šādu kodu:
import requests
def shorten_url(long_url): # Pieņemam garu saiti
response = requests.post("https://cleanuri.com/api/v1/shorten", data={"url": long_url}) # Nosūtam pieprasījumu uz API
result = response.json() # Rezultātu ņemam JSON formātā
return result["result_url"] # Iegūstam un atgriežam saīsināto saiti
if __name__ == "__main__":
print("Pārbaudām funkciju shorten_url")
print(shorten_url("https://google.com/"))
Ja jūs pamēģināsiet palaist šo programmu, tā izdos saīsinātu saiti uz Google.
Paši rediģējiet failu browser.py, lai filmu sarakstam tiktu pievienotas jau saīsinātas saites uz filmām.
Lai to izdarītu, jums ir jāimportē funkcija shorten_url un jāizmanto to vietā, kur informācija par filmu tiek pievienota sarakstam.
Beigās izveidojiet un nosūtiet komitu, pārslēdzieties atpakaļ uz galveno zaru, pārnesiet tajā izmaiņas un nosūtiet uz GitHub.
Darba nodošana
Jāiesniedz saite uz repozitoriju, kuru izveidojāt sākumā (piemēram, https://github.com/kitaminka/cinema-data).